In January 2026, archive.today targeted this blog with a distributed denial of service (DDoS) in an attempt to take offline a blog post I had written about them back in 2024. In February, I published a blog post about this attack. Here’s what happened next.
First-order effects
The traffic chart below pretty much tells the story:
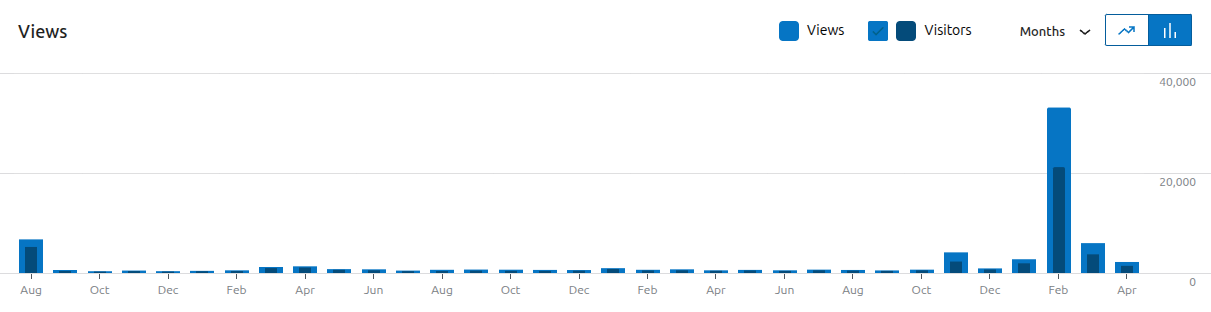
The blip on the left is the original blog post in August 2023, which garnered around 5,000 readers when first published. A slow trickle over the next two and half years added another 5,000, totalling some 10,000 all in.
The second blip was news reporting in November 2025 about the FBI subpoena on archive.today’s domain registrar, which brought in around 3,000 additional readers.
The attack started in January 2026, and I published my blog post about it on February 1st. It made the front page of Hacker News and was covered by ArsTechnica, TechCrunch and a number of other tech publications, bringing in over 40,000 readers by April. In other words, the attempt to suppress my post was considered anywhere from 4 to 13 times more interesting than the original post, a neat measure of the Streisand effect in action. The actual ratio is doubtless even more lopsided, since I can only measure the fraction of readers who clicked through to my blog.
The story was covered by exactly one mainstream media outlet that I know of, Finland’s largest newspaper Helsingin Sanomat, who reached out and interviewed me. Somewhat to my surprise, while the resulting article linked to my blog, only a few hundred readers bothered to click on the link. Apparently this was too niche a topic, and the story being in an obscure language and behind a paywall didn’t help.
Second-order effects

Something neither I nor, I suspect, the archive.today maintainer expected was that Wikipedia picked up on this too, kicking off a formal Request for Comments (RFC) on what should be done to the numerous archive.today links on the site. Hundreds of people chimed in, the debate revolving largely on whether the diffuse harm of roping unwitting Wikipedia readers into participating in a DDoS outweighed the utility of pointing those same readers to archived copies of otherwise ephemeral web pages.
The consensus was already leaning towards removal, when archive.today sealed the deal with another spectacular own goal: they were spotted injecting my name into a series of archived articles that had nothing to do with me. A Wikipedia editor pretty much summed up the reaction:
Honestly, I’m kind of in shock. Just to make sure I’m understanding the implications of this: we have good reason to believe that the archive.today operator has tampered with the content of their archives, in a manner that suggests they were trying to further their position against the person they are in dispute with???
archive.today quickly backpedaled, reverting their own edits, but the damage was done. On February 20, the RFC was concluded with the decision that new links to archive.today would be banned and old ones would be replaced with links to other archives.
This decision is more consequential than it might seem. When the RFC kicked off, Wikipedia contained nearly 700,000 links to archive.today, making it almost certainly their single largest source of incoming traffic. Since Wikipedia does not track clicks on external links, we have no way to measure exactly how much traffic it sends to archive.today, but the stream of users and the resulting ad revenue is surely significant, and so is its loss.
Final ripples

The DDoS continued unabated for several months. Since my blog is hosted on WordPress.com with a flat fee plan, there was no financial impact on me. It presumably cost Automattic a few extra CPU cycles, but they also collected every cent of the ad revenue from those 40,000 hits, so I’m pretty sure they still ended up a few bucks ahead.
Around June 5, the DDoS directly towards my site was quietly halted, first by changing the ping frequency from 3 times per second to once every 50 minutes, and a few days later by removing the code entirely. Instead, the maintainer appears to have found a new object for their ire: Wikipedia itself.
archive.today and Wikipedia have quite a bit of history. archive.today initially forcibly injected itself into Wikipedia with a massive, unauthorized bot campaign, leading to Wikipedia banning the site in 2013. There were several attempts to reverse the ban, with the third of these succeeding in 2016, with the optimistic summary that “we should at least try un-blacklisting archive.is, and seeing what happens“.
During and after the RFC, archive.today’s maintainer appears to have been quite active in Wikipedia discussions under a series of aliases like this one, which got banned for being a little too transparent in its vandalism. And there’s another complicated subthread involving “Nora”, whose identity was apparently purloined by the maintainer, pleading for her name to be removed from Wikipedia.
Around June 11, the dispute suddenly escalated. After apparently making the wild accusation that “the sole purpose of the discussion was to generate media hype while secretly continuing to exploit the free service“, archive.today started redirecting Wikipedia users clicking on archive.today links to the Tehran Times (video). This protest didn’t last long, and the message they were trying to send Wikipedia remains unclear, but this act of cutting off their own nose to spite their face effectively removed the last vestiges of the site’s usefulness to Wikipedia’s editors and readers.
Wikipedia countered by removing its referrer, making traffic from Wikipedia indistinguishable from any other request, and in response another distinctly sus anonymous user threatened to “simple (sic) delete all the pages linked from the Wikipedia“. Before they could make good on this threat, though, the final banhammer came down: archive.today and its many aliases were globally blacklisted on June 15, preventing any links to archive.today or its many aliases from being saved, and existing citation templates were modified to stop rendering any existing links to the site.
Conclusion

archive.today has been fully banished from Wikipedia and it’s highly unlikely they will change their mind again. Aside from the occasional blip in availability, archive.today itself remains up.
Thanks to a kind reader, gyrovague.gay exists now, and by clicking on it you, too, can contribute to a cause that I’m sure is near and dear to the archive.today maintainer’s heart, namely LGBTIQ rights in Ukraine.
On a more serious note, the world still needs an archive site that is reliable, censorship-resistant and under sane management. Alas, copyright laws conspire to make this unlikely, but the opportunity is there for the taking.
